最終更新日:2021/3/11
オブジェクト自体はベクター殿のストレージをお借りしています。
https://www.vector.co.jp/soft/winnt/hardware/se515149.html
このアプリケーションの基本はWebPage内に書き込まれたURLを抽出し一括ダウンロードする単純ツールです。
現バージョンでは埋込リンクの抽出や、ソースコードを手動で操作してURLを抽出するような手順も踏めるようになっています。このようなツールはJavaとかで作成すべきなのかと思いますが、敢えてDotNetコンポーネントの使用法を勉強も兼ねNI-LabVIEWで作成しています。
そのためファイルサイズの大きなランタイムエンジンを必要とするというビハインドを抱えています。2ちゃんねるの書込を一覧し、リンク情報を抽出して、特定フォルダに一括ダウンロードすることを意図しています。
リンク先をクリックするとポップアップページを介することになりこれを面倒とする方の使用を想定しています。
※ダウンロード後にフォルダ内をExplorer等で一覧表示出来ればよしという考えです。
※抽出URLは拡張子で篩い分けできるようにしています。URL抽出以外にも関連機能を追加しています。
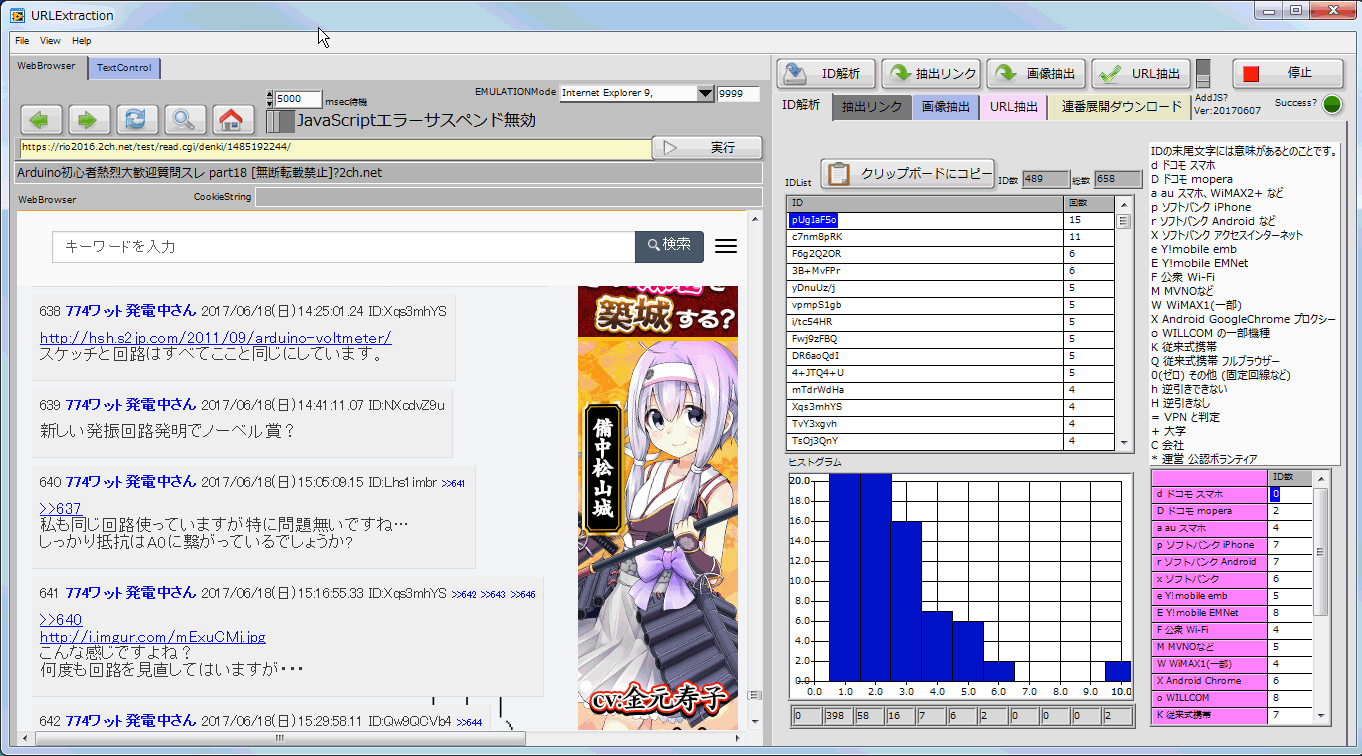
- 2ちゃんねるの書込者IDの書込数順リストアップ
- 連番ドキュメントのダウンロード支援
V1.1では以下の修正・機能追加を施しました。
- Windowを左右に分けて一方のみに表示が出来るように修正しました。
メニューバーのViewから選択できます。- 埋込リンクを抽出・フルパスリストアップをするようにしました。
拡張子による篩い分けをしてダウンロードも可能です。- urlmon.dllを使うのを止めて、WebClient::DownloadFileAsyncを使っています。
V1.2では以下の修正・機能追加を施しました。
- Web作成者が_blank設定したリンク設定を意図的に_self設定に変更して使用する機能を組み込みました。
- クッキー文字列を表示するようにしました。
- 外部URLリストファイルを読み込んでダウンロードする機能を追加しました。
- URL抽出機能においてフォルダパスを自動生成する機能を追加しました。
- ブラウザ内のリンクボタンを押したときにURLパス表示を更新するようにしました。
- ブラウズしているページのタイトルを表示するようにしました。
- 2chのID末尾の文字を分類する機能を追加しました。
V1.3では以下の修正・機能追加を施しました。
- URLリンクの文字列検索方法を修正しました。
“HREF”大文字小文字の区別をしないようにしました。- URLリンクの文字列検索でJavaScriptで作成された文字列を含めるかどうかを選択するようにしました。
- URLリンクの切り出しをテキストエディタライクに融通が利くように、WebPageのソースを表示出来るテキストエディット画面を追加しました。この画面にURLを切り出す為の検索・置換機能を追加しました。
- 連番展開ダウンロード機能を発展させ、一つ上位のベージリストをファイルで読み込んで、新規用意した『展開DL開始』を実行することで、読み込んだファイル内のURLを表示して、ページタイトル或いはパス階層を読み込んで、フォルダを作成し、そのページにリンクされているURLを抽出・拡張子で篩に分けながらダウンロードを実施します。
ページ毎にフォルダ分けされますので、ダウンロードをバッチ処理化出来ます。- 上記機能のためにプログレスバーを追加しました。
- ファイルダウンロード時のメモリキャッシュを強制的にクリアする機能を追加しました。“EmptyStandbyList”と云う機能を実行します。
- 前回実行後の情報を次回起動時に反映したいので、環境ファイルを作ることにしました。
- タブを色分けできるようにしました。ただ、環境ファイルでの設定のみです。
- WebBrowserのDocumentCompleteイベントを取得するように修正しました。少しでも応答無しを避けたいが為です。
V1.3.1では以下のバグ修正・機能追加を施しました。
- アプリケーション名に問題がありましたので修正しました。
UserAgentの確認機能でレジストリにアプリケーション名を登録しているのですが、どうも辻褄の合わない部分があったようで、IE7相当からの変更がうまくゆかない場合がありました。この部分を見直しました。- 合わせて、変更できるようにリング選択できるようにしました。
- 環境ファイルフォーマットを更新しています。
V1.4では以下のバグ修正・機能追加を施しました。
- 『画像抽出』機能で得られるURLリストに於いて、ダブルクオートが残っているというバグを直しました。
- URL入力欄をリスト選択出来る制御器(コンボボックス)に変更しました。
URL更新の最新10項目を選択出来るようにしました。- URL抽出におけるリストから、選択行をダブルクリックすると、そのURLを実行する様に対応しました。
- 画像抽出/URL抽出 実行時に保存先フォルダパスを実行したページのタイトルをフォルダ名に出来るようにしました。
- タブの色を変更出来るようにしました。
ソフトウェア必要条件:
- OS Windows7sp1/Windows10 ※DotNetコンポーネントの更新を要求される場合があります。
- LabVIEW2016ランタイムエンジンを使用
LVURLExtractionのインストール
本ソフトウエアにはインストーラを用意しています。LabVIEW2016ランタイムエンジンを含めてしまうと200MB超になり、Vectorさんでの扱いは申し訳ないので、実態のみのインストーラです。
ランタイムエンジンは日本NIのサイトからダウンロードしてください。
https://www.ni.com/download/labview-run-time-engine-2016/6066/en/
一応以下のサイトにLabVIEW2016ランタイムエンジンを含めたインストーラを置いておきます。
200MBあります。インストーラ(ランタイムエンジン込み) 1.4 約215MB(ZIP圧縮) インストーラ(実態のみ) 1.4 約7MB(ZIP圧縮) ソースコード(Project)も置いておきます。意図的にLabVIEW2014に変更しました。
※LabVIEW2014にはHomeEditionが有ります。1万円以下で購入できることもあり、ソース提供はこのバージョンで行うべきだと考えました。Project 1.4 約4MB(ZIP圧縮) アンインストールするには、
LVURLExtraction概観:
LVURLExtractionは、次の機能を有します。
- DotNetコンポーネントであるWebBrowserコントロールを使用してホームページのブラウズが出来ます。
※WebBrowserコントロールはIE7相当とのことです。メニューバー>>Help>>GetUserAgent の実行で確認します。- 表示しているページからURL相当の文字列を抽出してリストアップします。
- 表示しているページに埋め込まれているURLをフルパスにしてリストアップします。
- 表示しているページのソースコードをTextControlタブ側の制御器に表示します。
また、このソースをレタッチできます。
ソースコード文字列内からのURL抽出も可能です。- URL相当の文字列リストを順に所定のローカルフォルダにダウンロードします。
- 2ちゃんねるのスレッド表示をした際、IDリストをピックアップし、書込回数の多いID順にリストアップします。
- 2ちゃんねる等で連番リンクの一部のみ紹介しているケースがあります。そのようなケースの連番ダウンロード支援をします。
- タブカラーを変更出来るようにしました。
- 実行URLを最大10件キャッシュするようにしました。
注意事項
- 2ちゃんねる表示はJavaScript応答の都合で“応答なし”状態に陥る場合があります。頻発するような場合、
『JavaScriptエラーサスペンド無効』にしてください。実行できないScript毎にダイアログが出ますので対応願います。この方法だと“応答なし”状態を回避できる可能性があります。※5秒以上裏処理が連続しないように出来るため。- このアプリケーションでは「target="_blank"」を強制的に「target=""」に置き換える等の対策を実施しています。しかし完全ではありません。別Windowが出てきた場合、そのWindowは閉じてください。
動作確認状況
動作確認した環境は以下の通りです。
- Windows7SP1(build7601)x64
- Windows10Home(build14393)x64
- Windows10Pro(build14393)x64
ダウンロードした画像ファイルをAcrobatで結合してPDF化して管理することが多いのですが、バッチ処理する方法を検討中です。
自分のPC環境下にはAdobe Acrobat Standard DC(2015)がインストールされているのですが、なかなか自動化できません。
現状は作成したフォルダを右クリックして『ファイルをAcrobatで結合』を実行して作成されたPDFに対して、プロバティ設定を施し保存しています。そうすることで次回開くと右綴じの見開き頁やら画面に1頁割付が出来てそれはそれで便利です。LVURLExtractionにボタンを追加して、ページ内画像ダウンロード完了後に続けてPDF化のバッチ処理が実現出来ないか検討しています。
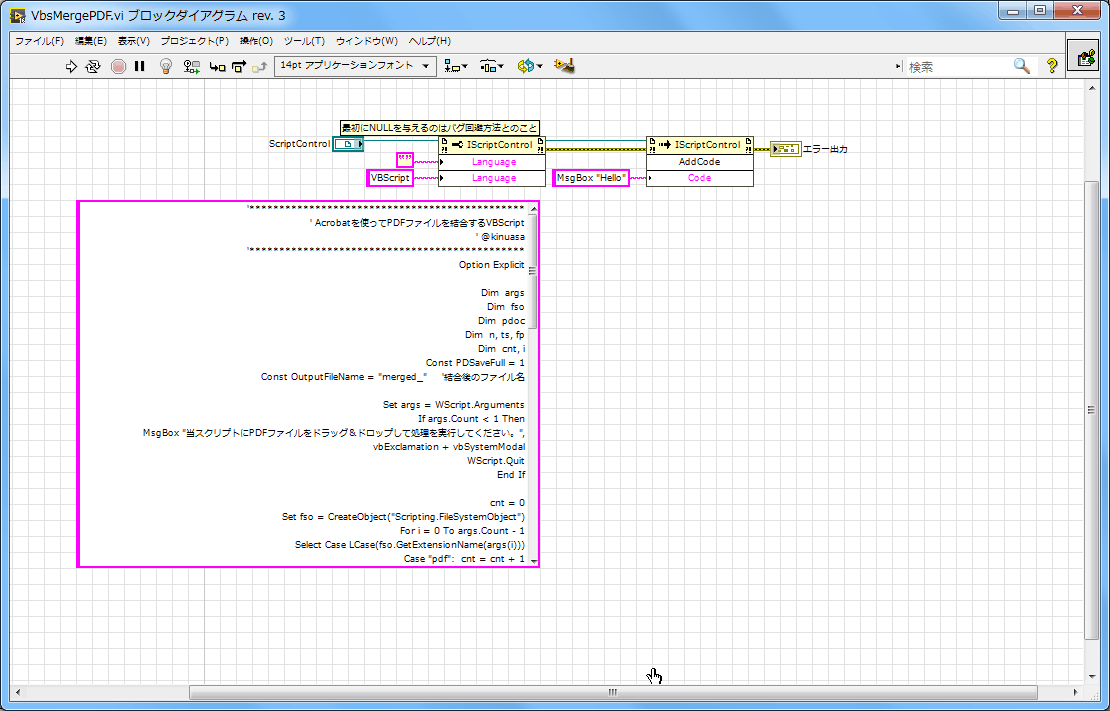
'********************************************** ' Acrobatを使ってPDFファイルを結合するVBScript ' @kinuasa '********************************************** Option Explicit Dim args Dim fso Dim pdoc Dim n, ts, fp Dim cnt, i Const PDSaveFull = 1 Const OutputFileName = "merged_" '結合後のファイル名 Set args = WScript.Arguments If args.Count < 1 Then MsgBox "当スクリプトにPDFファイルをドラッグ&ドロップして処理を実行してください。", vbExclamation + vbSystemModal WScript.Quit End If cnt = 0 Set fso = CreateObject("Scripting.FileSystemObject") For i = 0 To args.Count - 1 Select Case LCase(fso.GetExtensionName(args(i))) Case "pdf": cnt = cnt + 1 Case "jpg": cnt = cnt + 1 Case "jpeg": cnt = cnt + 1 Case "png": cnt = cnt + 1 End Select Next If cnt < 2 Then MsgBox "2個以上のPDF,画像ファイルを選択してください。", vbExclamation + vbSystemModal WScript.Quit End If '出力先設定 n = Now() ts = Year(n) & Right("0" & Month(n), 2) & Right("0" & Day(n), 2) & Right("0" & Hour(n), 2) & Right("0" & Minute(n), 2) & Right("0" & Second(n), 2) fp = fso.BuildPath(fso.GetFile(args(0)).ParentFolder.Path, OutputFileName & ts & ".pdf") With CreateObject("AcroExch.PDDoc") If .Create = True Then Set pdoc = CreateObject("AcroExch.PDDoc") For i = 0 To args.Count - 1 Select Case LCase(fso.GetExtensionName(args(i))) Case "pdf": If pdoc.Open(args(i)) = True Then .InsertPages .GetNumPages() - 1, pdoc, 0, pdoc.GetNumPages() - 1, True pdoc.Close End If Case "jpg": If pdoc.Open(args(i)) = True Then .InsertPages .GetNumPages() - 1, pdoc, 0, pdoc.GetNumPages() - 1, True pdoc.Close End If Case "jpeg": If pdoc.Open(args(i)) = True Then .InsertPages .GetNumPages() - 1, pdoc, 0, pdoc.GetNumPages() - 1, True pdoc.Close End If Case "png": If pdoc.Open(args(i)) = True Then .InsertPages .GetNumPages() - 1, pdoc, 0, pdoc.GetNumPages() - 1, True pdoc.Close End If End Select Next Set pdoc = Nothing .Save PDSaveFull, fp .Close End If End With MsgBox "結合したPDFファイルを【" & fp & "】に保存しました。", vbInformation + vbSystemModal上記VBScriptは管理人:きぬあさ氏のブログ『初心者備忘録』で知り得たPDFを制御するVBScriptをレタッチしたモノです。
使い方ですが、
- スクリプトを『MergePDF.vbs』と云うファイル名で保存します。
- 結合したいファイルを纏めて『MergePDF.vbs』にドラッグ&ドロップします。
- merged_YYYYMMDDHHMMSS.pdfと云う名前で保存されます。
- PDFファイルしか結合できません。JPEG等の画像ファイルを結合するための手続きが判っていません。
- フォルダ名から結合のファイル名を求める必要があるのですが、その部分を直す必要があります。
上記スクリプトでは現在時刻を採用しています。- フォルダ内のファイルをリストアップする必要があります。
- VBScriptはWSHのサブセットという位置づけなのでしょうか?多分WindowsOSかであればそのままバッチファイルとして出来るようです。
- Adobeさんを当てに出来ない為、VBScriptで実現方法を検証し、組み込むのがいいのかな
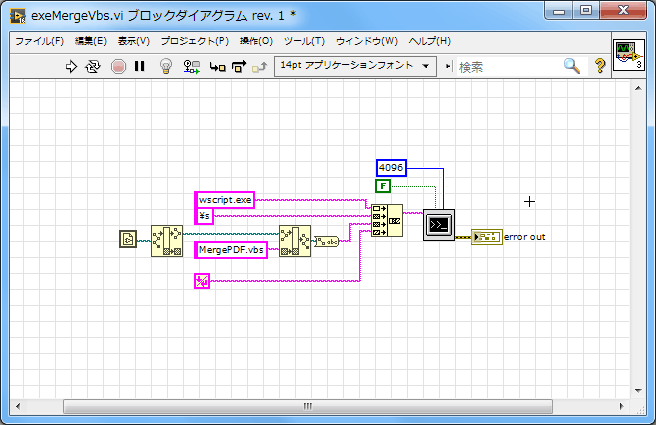
ちなみにVBScriptファイルをLabVIEWで実行する場合はSystemExecを使用して以下のように記述します。WSH下で実行するという事です。
ただ、この場合VBScriptに引数を与えることがうまく出来ないと思います。
そこで引数が必要な場合はActiveXのScriptControlを使ってコードを書くことになります。上記の例の場合、
PDFの画像結合の別案です。
ImageMagickというツールを使って
convert pg*.jpg pages.pdfという記述でjpgファイルを pages.pdf に変換できるという情報を得ました。
ImageMagickと云うツールはLinux以外の環境でも使えます。https://www.imagemagick.org/script/download.php
からダウンロード出来ます。
免責事項
本ソフトウエアは、あなたに対して何も保証しません。本ソフトウエアの関係者(他の利用者も含む)は、あなたに対して一切責任を負いません。
あなたが、本ソフトウエアを利用(コンパイル後の再利用など全てを含む)する場合は、自己責任で行う必要があります。本ソフトウエアの著作権はToolsBoxに帰属します。
本ソフトウエアをご利用の結果生じた損害について、ToolsBoxは一切責任を負いません。
ToolsBoxはコンテンツとして提供する全ての文章、画像等について、内容の合法性・正確性・安全性等、において最善の注意をし、作成していますが、保証するものではありません。
ToolsBoxはリンクをしている外部サイトについては、何ら保証しません。
ToolsBoxは事前の予告無く、本ソフトウエアの開発・提供を中止する可能性があります。
商標・登録商標
Microsoft、Windows、WindowsNTは米国Microsoft Corporationの米国およびその他の国における登録商標です。
Windows Vista、Windows XPは、米国Microsoft Corporation.の商品名称です。
LabVIEW、National Instruments、NI、ni.comはNational Instrumentsの登録商標です。
I2Cは、NXP Semiconductors社の登録商標です。
その他の企業名ならびに製品名は、それぞれの会社の商標もしくは登録商標です。
すべての商標および登録商標は、それぞれの所有者に帰属します。
ご使用のブラウザ情報は